factors_r = ["SP500", "DTWEXAFEGS"] # "SP500" does not contain dividends; note: "DTWEXM" discontinued as of Jan 2020
factors_d = ["DGS10", "BAMLH0A0HYM2"]Price momentum
One month reversal and 2-12 month momentum are two ends of the spectrum. The general trend indicates that positive acceleration leads to reversals or negative acceleration leads to rebounds. An unsustainable acceleration leading to reversal can reconcile the one-month reversal and 2-12 month momentum. The key is that it implies that acceleration is not sustainable.
# "Momentum, Acceleration, and Reversal"
def pnl(x):
return np.nanprod(1 + x) - 1order = 20momentum_df = returns_df.shift(order).rolling(width - order, min_periods = 1).apply(pnl, raw = False).dropna()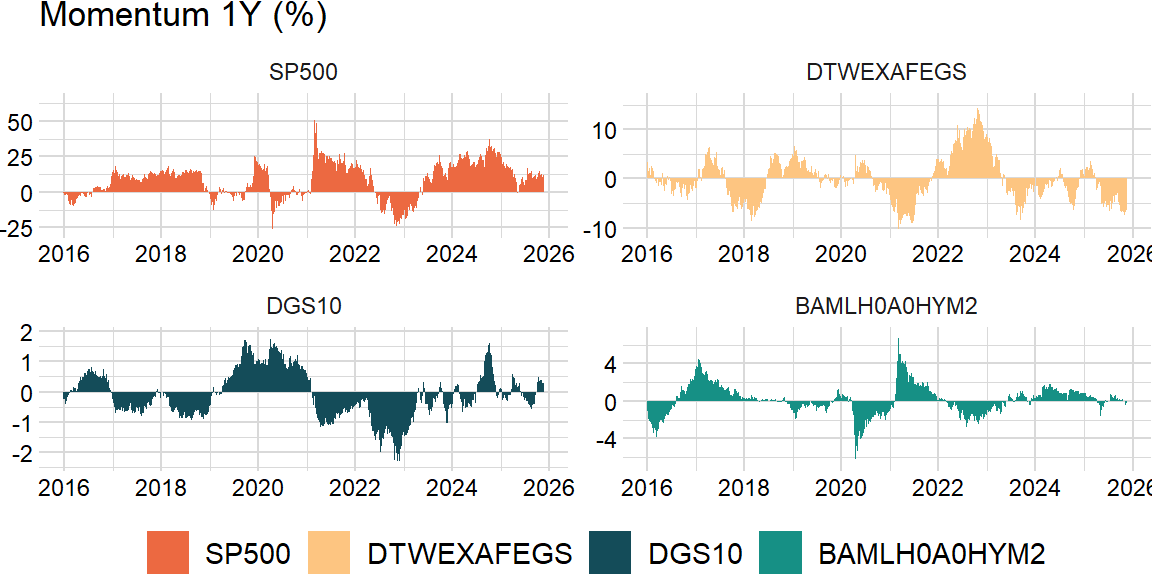
Time-series score
Suppose we are looking at \(n\) independent and identically distributed random variables, \(X_{1},X_{2},\ldots,X_{n}\). Since they are iid, each random variable \(X_{i}\) has to have the same mean, which we will call \(\mu\), and variance, which we will call \(\sigma^{2}\):
\[ \begin{aligned} \mathrm{E}\left(X_{i}\right)&=\mu\\ \mathrm{Var}\left(X_{i}\right)&=\sigma^{2} \end{aligned} \]
Let’s suppose we want to look at the average value of our \(n\) random variables:
\[ \begin{aligned} \bar{X}=\frac{X_{1}+X_{2}+\cdots+X_{n}}{n}=\left(\frac{1}{n}\right)\left(X_{1}+X_{2}+\cdots+X_{n}\right) \end{aligned} \]
We want to find the expected value and variance of the average, \(\mathrm{E}\left(\bar{X}\right)\) and \(\mathrm{Var}\left(\bar{X}\right)\).
Expected value
\[ \begin{aligned} \mathrm{E}\left(\bar{X}\right)&=\mathrm{E}\left[\left(\frac{1}{n}\right)\left(X_{1}+X_{2}+\cdots+X_{n}\right)\right]\\ &=\left(\frac{1}{n}\right)\mathrm{E}\left(X_{1}+X_{2}+\cdots+X_{n}\right)\\ &=\left(\frac{1}{n}\right)\left(n\mu\right)\\ &=\mu \end{aligned} \]
Variance
\[ \begin{aligned} \mathrm{Var}\left(\bar{X}\right)&=\mathrm{Var}\left[\left(\frac{1}{n}\right)\left(X_{1}+X_{2}+\cdots+X_{n}\right)\right]\\ &=\left(\frac{1}{n}\right)^{2}\mathrm{Var}\left(X_{1}+X_{2}+\cdots+X_{n}\right)\\ &=\left(\frac{1}{n}\right)^{2}\left(n\sigma^{2}\right)\\ &=\frac{\sigma^{2}}{n} \end{aligned} \]
def sd(x):
n_rows = sum(~np.isnan(x))
if n_rows > 1:
result = np.sqrt(np.nansum(x ** 2) / (n_rows - 1))
else:
result = np.nan
return result# volatility scale only
score_df = (momentum_df / momentum_df.rolling(width, min_periods = 1).apply(sd, raw = False)).dropna()# overall_df = score_df.mean(axis = 1)
# overall_df = overall_df / overall_df.rolling(width, min_periods = 1).apply(risk, raw = False)# score_df.insert(loc = 0, column = "Overall", value = overall_df)
# score_df = score_df.dropna()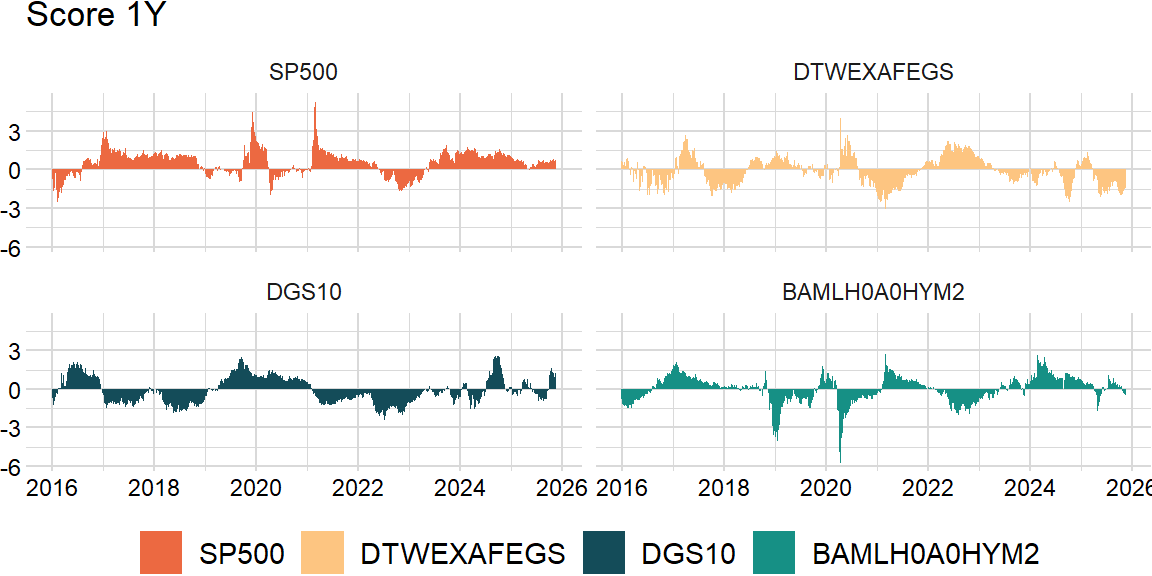
Outlier detection
import statsmodels.api as smInterquartile range
Outliers are defined as the regression residuals that fall below \(Q_{1}−1.5\times IQR\) or above \(Q_{3}+1.5\times IQR\):
- https://stats.stackexchange.com/a/1153
- https://stats.stackexchange.com/a/108951
- https://robjhyndman.com/hyndsight/tsoutliers/
def outliers(z):
n_cols = z.shape[1]
result_ls = []
for j in range(n_cols):
y = z.iloc[:, j]
if (n_cols == 0):
x = sm.add_constant(range(len(y)))
else:
x = sm.add_constant(z.drop(z.columns[j], axis = 1))
coef = sm.WLS(y, x).fit().params
predict = coef.iloc[0] + np.dot(x.iloc[:, 1:], coef[1:])
resid = y - predict
lower = resid.quantile(0.25)
upper = resid.quantile(0.75)
iqr = upper - lower
total = y[(resid < lower - 1.5 * iqr) | (resid > upper + 1.5 * iqr)]
total = pd.DataFrame({"date": total.index, "symbol": total.name, "values": total})
result_ls.append(total)
result = pd.concat(result_ls, ignore_index = True)
result = result.pivot_table(index = "date", columns = "symbol", values = "values")
return resultoutliers_df = outliers(score_df)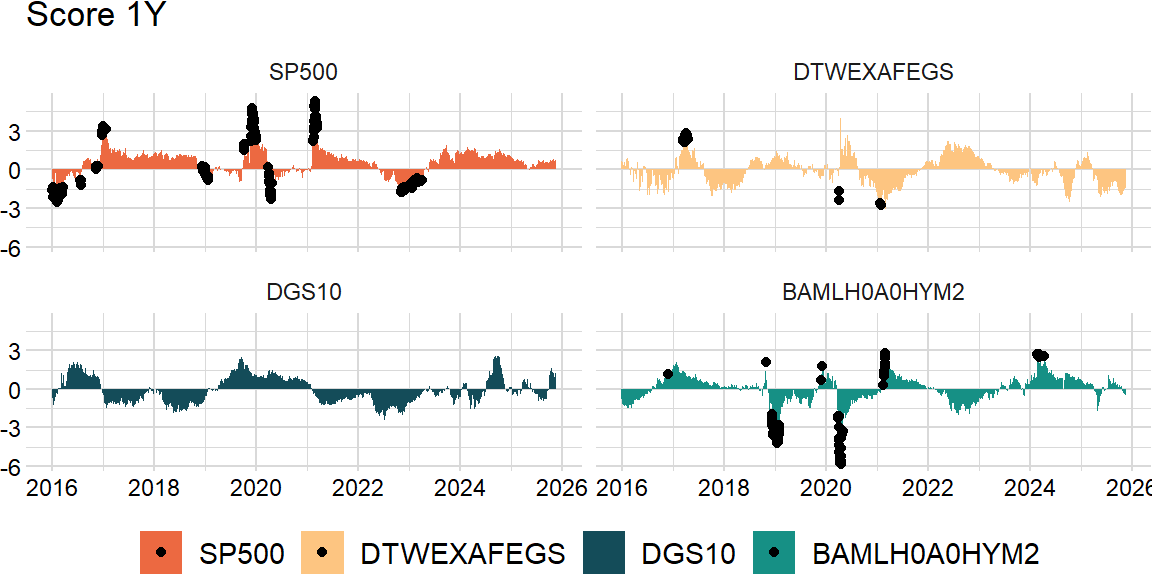
Contour ellipsoid
Granger causality
from scipy.stats import chi2\[ \begin{aligned} \left(R\hat{\beta}-r\right)^\mathrm{T}\left(R\hat{V}R^\mathrm{T}\right)^{-1}\left(R\hat{\beta}-r\right)\xrightarrow\quad\chi_{Q}^{2} \end{aligned} \]
- https://github.com/cran/lmtest/blob/master/R/waldtest.R
- https://en.wikipedia.org/wiki/Wald_test#Test(s)_on_multiple_parameters
- https://math.stackexchange.com/a/1591946
def granger_test(x, y, order):
# compute lagged observations
lag_x = x.shift(order)
lag_y = y.shift(order)
# collect series
df = pd.DataFrame({"x": x, "y": y, "lag_x": lag_x, "lag_y": lag_y})
x = sm.add_constant(df[["lag_y", "lag_x"]])
# fit full model
fit = sm.WLS(df["y"], x, missing = "drop").fit()
R = np.array([0, 0, 1])
coef = fit.params
r = 0 # technically a matrix (see Stack Exchange)
matmul = np.dot(R, coef) - r
matmul_mid = np.linalg.inv(np.atleast_2d(np.dot(R, np.dot(fit.cov_params(), R.T))))
wald = np.dot(matmul.T, np.dot(matmul_mid, matmul))
result = 1 - chi2.cdf(wald, 1)
return resultdef roll_lead_lag(x, y, width, order, p_value):
n_rows = len(x)
x_name = x.name
y_name = y.name
x_y_ls = []
y_x_ls = []
for i in range(width - 1, n_rows):
idx = range(max(i - width + 1, 0), i + 1)
x_y = granger_test(x.iloc[idx], y.iloc[idx], order)
y_x = granger_test(y.iloc[idx], x.iloc[idx], order)
x_y_status = (x_y < p_value) and (y_x > p_value)
y_x_status = (x_y > p_value) and (y_x < p_value)
x_y_ls.append(x_y_status)
y_x_ls.append(y_x_status)
result = pd.DataFrame({x_name: x_y_ls, y_name: y_x_ls}, index = x.index[(width - 1):])
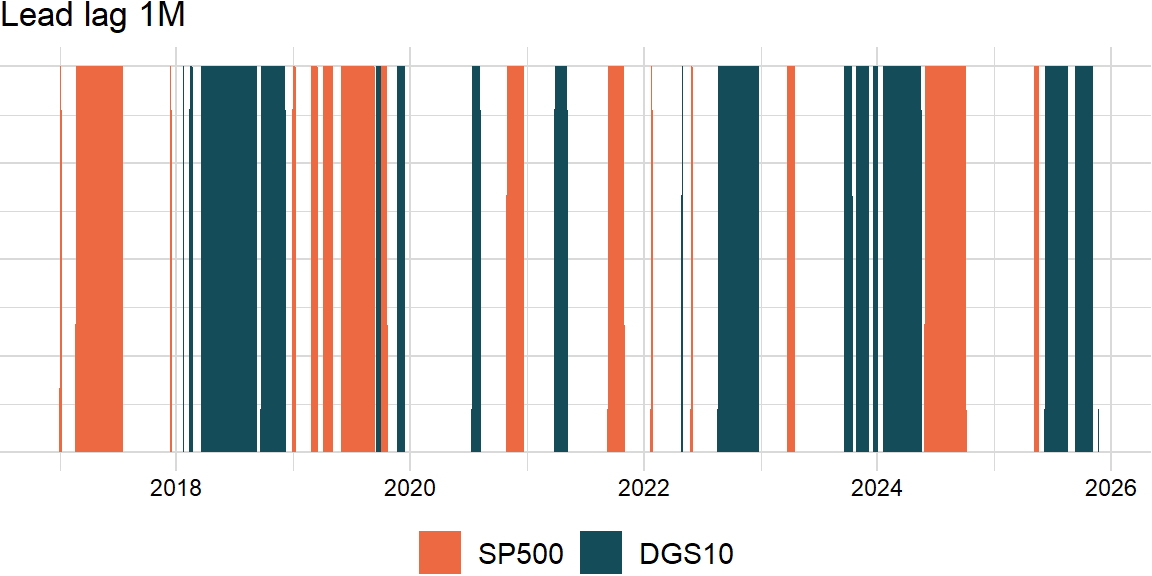
return resultp_value = 0.05score_x_df = score_df.loc[:, "SP500"]
score_y_df = score_df.loc[:, "DGS10"]lead_lag_df = roll_lead_lag(score_x_df, score_y_df, width, order, p_value)